|
A*|Dijkstra Algoritmi |
Introduzione:
L'algoritmo di ricerca A* é stato sviluppato dallo “Stanford Research institute” ed ampiamente utilizzato nel pathfinding. Esso rappresenta un'estensione dell'algoritmo di “Edsger Dijkstra”. Quest'ultimo è presente nel file di ricerca tuttavia ci siamo concentrati sul derivato A* in quanto offre prestazioni migliori grazie all'implementazione di varie euristiche che permettono un’esecuzione più "smart". In sintesi A* si occupa di tracciare un percorso ottimale tra più nodi di una griglia. Algoritmo:
Fase 1:
Inizialmente è opportuno definire una griglia per l'area di ricerca ottenibile attraverso un semplice array bidimensionale. Ciò permette di ottenere un numero gestibile di nodi rappresentanti un oggetto le cui proprietà di camminabilità, tra le altre, incidono sul percorso (path) ottenuto.
Fase 2:
Una volta definita l’area di lavoro del pathfinding è possibile avviare la ricerca del percorso più breve. A tal fine si identifica un punto iniziale (startPos) e controllando i nodi adiacenti si prosegue per l’obiettivo (endPos). Nello specifico l’algoritmo agisce nel seguente modo: 1 - Lo startPos viene inserito in un insieme “lista aperta” di nodi che potenzialmente fanno parte del percorso e quindi andranno esaminati in seguito. 2 - Vengono visionati tutti i nodi percorribili ?adiacenti al punto di partenza?. 3 - Si elimina lo startPos dalla lista aperta e si inserisce in un altro insieme “lista chiusa” di nodi che non hanno bisogno di essere esaminati per ora. 4 - Infine si sceglie uno dei nodi adiacenti nella “lista aperta” e si ripete il processo precedente come descritto in seguito.
Fase 3:
A questo punto è fondamentale determinare quali nodi “utilizzare” per la ricerca del percorso. La seguente equazione esprime in modo sintetico e illustrativo tale operazione: F_Score = G_Score + H_Score dove: G_Score = G (p,n) -> Costo del movimento per passare dal punto di partenza “p” a un dato nodo sulla griglia “n” attuale. H_Score = H (s,n) -> Costo ?stimato? del movimento da un nodo attuale “n” ad una destinazione finale “s”. Questo valore viene definito “euristico” in quanto non è possibile stabilire il percorso (presenza di ostacoli) prima di averlo effettivamente definito. Esso influenza fortemente i risultati ottenuti da A* e ne migliora sensibilmente l’efficacia. Si consideri che nel caso pessimo A* diviene un algoritmo di ricerca molto simile a Dijkstra. Vediamo un esempio per capire come vengono attribuiti i valori di costo per un percorso espressi tramite l'equazione precedentemente indicata: Poniamo il caso di avere due punti identificati sul piano cartesiano da una coppia di valori (x,y) rispettivamente per l'asse delle ascisse e quello delle ordinate. Indichiamo con G_Score la distanza tra i due.
startPos = (xs,ys)
endPos = (xe,ye)
G_Score (startPos,endPos) = v(xe - xs)² + (ye - ys)²
Esempio:
startPos = (0,0) endPos = (10,1) G_score(startPos,endPos) = v101 = ~10.4
Si consideri che in questo caso si prevede la formulazione delle diagonali. Semplicemente ogni spostamento verticale o orizzontale tra i nodi da startPos a endPos viene considerato con il costo di 1 e ogni movimento diagonale ?circa 1.414 per derivazione del T. Di P. Qualora l’esecuzione del percorso lo permetta è possibile assegnare un valore di 10 allo spostamento rettilineo e 14 a quello diagonale permettendo al calcolatore di interagire soltanto con numeri interi e quindi risparmiare risorse di sistema. Per quanto concerne H_Score sappiamo che può essere calcolato con varie metodologie. Vediamo l'esempio utilizzando l'implementazione euristica "Manhattan" che somma il numero totale di spostamenti orizzontali / verticali per raggiungere l'obiettivo. Esso ignora eventuali ostacoli che sono rappresentati dagli oggetti nodo con il parametro "walkability = false" restituendo una stima approssimativa della distanza rimanente. Si noti che più esso si avvicina realisticamente alla distanza di percorso e più l'algoritmo sarà veloce nel raggiungimento del goal. Adesso che siamo in grado di definire F_score come somma di G_score e H_score vediamolo in pratica. Poniamo il caso:
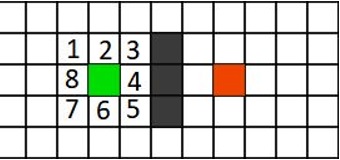
F_Score (pos.1) = 1.4 + 6 = 7.4
F_Score (pos.2) = 1 + 5 = 6
F_Score (pos.3) = 1.4 + 4 = 5.4
F_Score (pos.4) = 1 + 3 = 4
F_Score (pos.5) = 1.4 + 4 = 5.4
F_Score (pos.6) = 1 + 5 = 6
F_Score (pos.7) = 1.4 + 6 = 7.4
F_Score (pos.8) = 1 + 5 = 6
Possiamo evincere che il “best score” sarà rappresentato dalla pos.4 con un totale di 4 punti. Arrivati a questo punto l’algoritmo eseguirà le seguenti operazioni: 1 - Il nodo in pos.4 verrà “rilasciato” dalla lista aperta e aggiunto alla lista chiusa. 2 - Vengono controllati tutti nodi adiacenti ignorando quelli nella “lista chiusa” o non percorribili per aggiungerli alla “lista aperta” e il quadrato selezionato viene inserito tra i genitori dei nuovi. 3 - Se un nodo adiacente si trova nella “lista aperta” viene controllato il percorso per quella posizione allo scopo di verificare se è migliore. Nel caso non lo sia non viene eseguita alcuna azione, in caso contrario si definisce come nuovo “genitore”. 4 - Infine vengono riconsiderati i punteggi F_Score e G_Score del nuovo nodo.
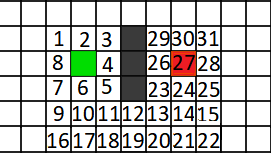
Si consideri la pos.4 come nodo attuale e si prosegua con il calcolo dei costi per i nodi figli. I nodi non percorribili sono caratterizzati dal riempimento grigio e ovviamente non verranno considerati come “papabili” per il percorso. La scelta si riduce ai nodi 3 e 5 che tuttavia risultano avere lo stesso punteggio (5.4). Ai fini dell’algoritmo non è rilevante quale dei due si sceglie, una soluzione immediata potrebbe essere quella di scegliere l’ultimo elemento aggiunto nella “lista aperta”. Prendendo quindi come riferimento il passaggio dal nodo in pos.5 possiamo considerare i punteggi per i suoi elementi adiacenti:
F_Score (pos.10) = 2 + 6 = 8
F_Score (pos.11) = 2.4 + 5 = 7.4
F_Score (pos.12) = 3.4 + 4 = 7.4
Nuovo “best score” = pos.12
F_Score (pos.13) = 4.4 + 3 = 7.4
F_Score (pos.18) = 3.4 + 6 = 9.4
F_Score (pos.19) = 3.8 + 5 = 8.8
F_Score (pos.20) = 4.8 + 4 = 8.8
F_Score (pos.23) = 4.4 + 3 = 7.4
Nuovo “best score” = pos.23
F_Score (pos.14) = 5.4 + 2 = 7.4
F_Score (pos.24) = 5.8 + 1 = 6.8
F_Score (pos.26) = 7.2 + 1 = 8.2
F_Score (pos.27) = 6.8 + 0 = 6.8
endPos = nodo 27.
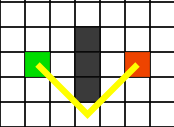
Note su Dijkstra e altre euristiche: Dijkstra è essenzialmente lo stesso algoritmo di A* ma sprovvisto di euristica. Il suo comportamento sarà analogo ma cercherà di espandersi in egual modo su ogni direzione fino al raggiungimento dell’obiettivo. Questa implementazione può essere utile qualora non si sappia distintamente dove si trova la destinazione. Poniamo il caso di avere più obiettivi ma si scelga di approcciare il più vicino, in questo caso un’alternativa sarebbe richiamare ripetutamente A* e valutare i vari percorsi oppure utilizzare Dijkstra che potrebbe risultare la soluzione più efficiente. Per quanto concerne l’euristica “Manhattan” abbiamo già definito che si occupa di descrivere il percorso stimato sul piano cartesiano attraverso il movimento quadridimensionale in forma rettilinea: manhattan: function(dx, dy){ return dx + dy; }, Si noti che dx rappresenta la differenza dai punti presi in considerazione sull’asse delle ascisse e dy analogamente sulle ordinate. L’euristica euclidea invece adotta un comportamento simile ma ammette il movimento diagonale :
euclidean: function(dx, dy) { return Math.sqrt(dx * dx + dy * dy); },
Ovvero:
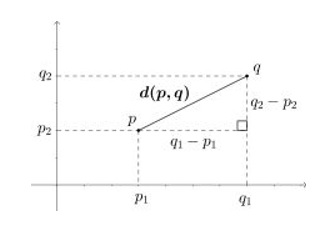
d(p,q)² = (q1 - p1)² + (q2 -p2)² ->
d(p,q) = v(q1 - p1)² + (q2 - p2)² + … + (qn - pn)² ->
√∑n[i=1](qi - pi)²
Di seguito altre euristiche :
octile: function(dx, dy) { var F = Math.SQRT2 - 1; return (dx < dy) ? F * dx + dy : F * dy + dx; };
chebyshev: function(dx, dy) { return Math.max(dx, dy); };